Ruszył news.google.pl - czekamy teraz na reakcję polskich wydawców prasy
 Jak wiadomo (gdyż wielu już o tym napisało) - dziś ruszyła polskojęzyczna wersja googlowego serwisu agregującego najświeższe doniesienia z całej Sieci, tj. news.google.pl. Niektórzy pamiętają pewnie, że w Belgii serwis ten stał się przyczyną interesującego sporu sądowego, który doprowadził m.in. do tego, że na stronie głównej tamtejszej wersji serwisu Google opublikowano nawet wyrok sądu. Mam na myśli spór belgijskich wydawców prasy zrzeszonych w organizację Copiepresse (por.Google przegrało w sporze z belgijskimi wydawcami prasy). Ciekawe byłoby poznanie jakiegoś komentarza przedstawicieli naszego, rodzimego rynku prasowego. W Polsce odpowiednikiem Copiepresse jest chyba Izba Wydawców Prasy. W notatce prasowej, którą mi przesłano, widzę, że Google powołuje się na prawo cytatu i duży nacisk (to subiektywne wrażenie) położono na to, że ten serwis jest legalny.
Jak wiadomo (gdyż wielu już o tym napisało) - dziś ruszyła polskojęzyczna wersja googlowego serwisu agregującego najświeższe doniesienia z całej Sieci, tj. news.google.pl. Niektórzy pamiętają pewnie, że w Belgii serwis ten stał się przyczyną interesującego sporu sądowego, który doprowadził m.in. do tego, że na stronie głównej tamtejszej wersji serwisu Google opublikowano nawet wyrok sądu. Mam na myśli spór belgijskich wydawców prasy zrzeszonych w organizację Copiepresse (por.Google przegrało w sporze z belgijskimi wydawcami prasy). Ciekawe byłoby poznanie jakiegoś komentarza przedstawicieli naszego, rodzimego rynku prasowego. W Polsce odpowiednikiem Copiepresse jest chyba Izba Wydawców Prasy. W notatce prasowej, którą mi przesłano, widzę, że Google powołuje się na prawo cytatu i duży nacisk (to subiektywne wrażenie) położono na to, że ten serwis jest legalny.
News.google.pl agreguje doniesienia TVN24, Rzeczpospolitej, Gazety Wyborczej, serwisu TVP, Dziennika, Polityki, Newsweek Polska, Trybuny, Pulsu Biznesu, Głosu Nauczycielskiego... A więc to nie tylko prasa w sensie tradycyjnym, papierowym. To również serwisy internetowe telewizji, ale również radiowe serwisy internetowe (Polskie Radio - Radio VOX FM). Na razie serwis sygnalizuje, że indeksuje stale aktualizowane informacje z 300 źródeł (wersja USA ma 4,500 źródeł). Z punktu widzenia pracy polegającej na ciągłym analizowaniu doniesień medialnych na temat "prawnych aspektów społeczeństwa informacyjnego" - narzędzie indeksujące bieżące źródła jest bardzo przydatne. Można linkować do nowych wątków (chociaż główny nurt nie linkuje, bo czytelnicy przechodziliby do reklamowej konkurencji), można śledzić te nowe doniesienia. Oczywiście podnosi też poprzeczkę dziennikarzom, bo wyraźnie widać w takim zestawieniu kto od kogo przepisuje w pogoni za "unikalnymi użytkownikami", którzy mogą obejrzeć prezentowane przy okazji artykułów kreacje reklamowe. Pojawienie się takiego serwisu musi jednak zepsuć nastrój Prezesowi PAP, p. Piotrowi Skwiecińskiemu (por. Rola agencji informacyjnych w społeczeństwie... informacyjnym).
Google powołuje się na prawo cytatu, ale przypomnijmy, że 5 września 2006 roku, sąd w Belgii nakazał Google usunięcia z Google News treści (cytatów) pochodzących z francuskojęzycznych gazet. Model biznesowy reprezentowany przez Google trafił do Polski i jestem przekonany, że nie pozostanie bez echa (por. Czy jest o co kruszyć kopie?, Kopia lokalna a monopol na informacje, RSS, prawa autorskie a zasady współżycia społecznego, ale również Ciąg dalszy belgijskiego sporu wydawców z Google, czy Negocjacje MSN po wyroku w sprawie Google i Chcemy oglądalności bez pośredników - belgijskie orzeczenie przeciwko Google - być może najwięksi gracze na rynku informacyjnym będą mieli jakiś udział w przychodach?). Można spodziewać się też pierwszych sytuacji związanych z manipulacją informacją związaną z emitentami notowanymi na Warszawskiej Giełdzie Papierów Wartościowych (por. Rzetelność automatów i prasy (na przykładzie linii lotniczych i dziennikarskiej relacji o łańcuszku)).
Na stronie Izby Wydawców Prasy nie widzę jeszcze żadnego komunikatu, który komentowałby uruchomienie nowego serwisu Google. Jestem jednak przekonany, że dla Izby uruchomienie tego serwisu nie było zaskoczeniem. Przypuszczam nawet, że Google - pamiętając poniżej przywołaną, w formie zrzutu ekranowego, sytuację w Belgii, jakoś próbował dogadać się z dużymi wydawcami. Wiadomo przecież, że ważna jest nie tylko wolność słowa i możliwość publikowania tego, co się chce, ale również to, by czytelnicy czytali to o czym piszą wszyscy właśnie u nas (por. Ograniczanie i kontrola dostępu oraz kanałów dystrybucji). Tymczasem przypominam, że Podziwiam Google i jestem przerażony.
Prawo cytatu tekstu przy publikacjach tego typu nie jest jedynym problemem. Innym jest np. kopiowanie zdjęć, które ilustrują wybrane przez Google źródła. Jeśli to "aktualne zdjęcia reporterskie", to istotnie znajdziemy w ustawie stosowną licencję (chociaż przecież mowa tam również o wynagrodzeniu). Trzeba również uwzględnić problem korzystania z baz danych, które są w Europie (a więc również w Polsce) chronione sui generis...
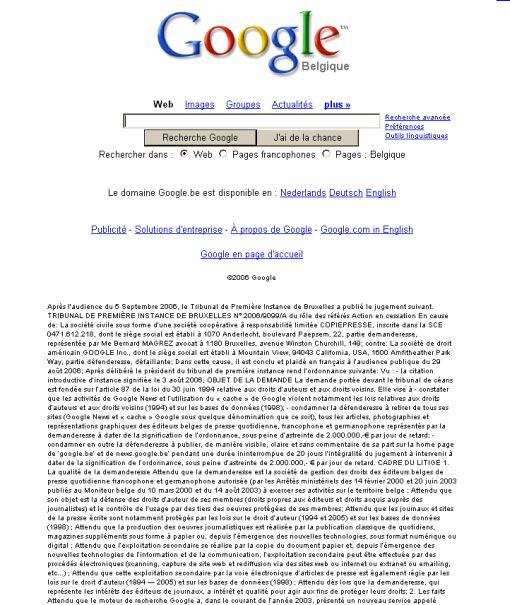
Jeden z efektów orzeczenia z 2006 roku, w którym sąd nakazał Google umieszczenie na okres 5 dni informacji na temat wydanego wyroku na głównej stronie belgijskiego portalu Google.be. Powyżej screenshot fragmentu informacji o orzeczeniu na głównej stronie Google.be (tekst był znacznie dłuższy, ponad 1200px "w dół")
Jak wspomniałem - otrzymałem notatkę prasową od firmy public relations, która obsługuje medialnie pojawienie się nowego serwisu Google. Można tam przeczytać:
Google News to dzieło Krishny Bharata. Tragiczne wydarzenia z 11 września 2001 r. uświadomiły mu, jak trudno jest znaleźć pochodzące z różnych źródeł artykuły na ten sam temat – na przykład w celu porównania, czym różni się podejście dziennikarzy w Indiach od podejścia dziennikarzy w USA. Wizja Krishny jest zgodna z podstawowymi zasadami dziennikarstwa – informować ludzi o ważnych dla nich wydarzeniach, otwierać umysły na nowe głosy, zachęcać do interpretacji wydarzeń z różnych punktów widzenia..
Google News przypomina wyszukiwarkę Google - gromadzi znalezione w internecie informacje, tworzy ich indeks i wyświetla użytkownikom wyniki wyszukiwania. Tak jak w przypadku wyszukiwarki, celem jest podawanie najtrafniejszych wyników, dlatego też wyniki generowane są całkowicie automatycznie - za pomocą robotów indeksujących. Nagłówki wyświetlane na stronie głównej Google News są wybierane przez algorytm komputerowy, oparty na wielu czynnikach, takich jak popularność poszczególnych wiadomości i liczba witryn internetowych, w których są one publikowane. Przede wszystkim uwzględniana jest liczba oryginalnych artykułów napisanych i opublikowanych przez redakcje w celu określenia wagi tematu, na którą ma również wpływ jego aktualność.
W Google News pochodzące z ponad 300 polskojęzycznych źródeł materiały na ten sam temat są umieszczane w jednej „grupie wiadomości". Serwis Google News w pełni przestrzega międzynarodowych praw autorskich i praw miejscowych w każdym regionie, w którym jest dostępny. Jeśli użytkownik chce przeczytać cały artykuł lub zobaczyć zdjęcie w pełnych rozmiarach, musi kliknąć link i przejść do witryny wydawcy. Krótkie fragmenty są wyświetlane użytkownikom Google News w celu udostępnienia im linków do tych witryn. Jest to w pełni zgodne z prawami autorskimi, które zezwalają na wykorzystywanie treści w ograniczonym zakresie bez zezwolenia właściciela praw. Dzięki temu zapisowi gazetom wolno np. podawać w recenzjach krótkie cytaty z książek chronionych prawami autorskimi.
VaGla.pl Prawo i Internet jest jednym ze źródeł indeksowanych w ramach news.google.com (por. Źródło dla news.google.com i innych, regionalnych). Notatki da się znaleźć w wynikach wyszukiwania, chociaż nie wiem, czy ten serwis załapie się również na "wybór" doniesień na stronie głównej. Tam jest tylko "Świat", "Polska", "Gospodarka", "Nauka/technika", "Sport" i "Rozrywka" i gdybym miał się gdzieś przypisać, do którejś z tych kategorii, to chyba nie wiedziałbym zbytnio gdzie.
Aktualizacja: dodałem zrzut ekranu:
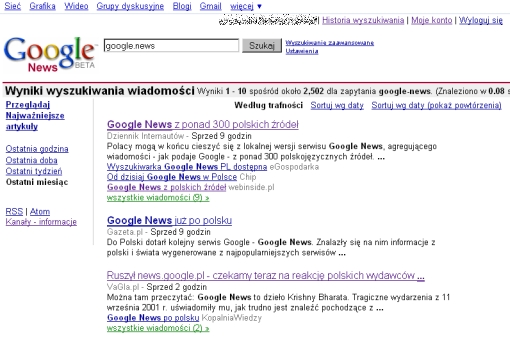
Zrzut ekranu serwisu news.google.pl z doniesieniami na temat uruchomienia news.google.pl
- Login to post comments
Piotr VaGla Waglowski

Piotr VaGla Waglowski - prawnik, publicysta i webmaster, autor serwisu VaGla.pl Prawo i Internet. Ukończył Aplikację Legislacyjną prowadzoną przez Rządowe Centrum Legislacji. Radca ministra w Departamencie Oceny Ryzyka Regulacyjnego a następnie w Departamencie Doskonalenia Regulacji Gospodarczych Ministerstwa Rozwoju. Felietonista miesięcznika "IT w Administracji" (wcześniej również felietonista miesięcznika "Gazeta Bankowa" i tygodnika "Wprost"). Uczestniczył w pracach Obywatelskiego Forum Legislacji, działającego przy Fundacji im. Stefana Batorego w ramach programu Odpowiedzialne Państwo. W 1995 założył pierwszą w internecie listę dyskusyjną na temat prawa w języku polskim, Członek Założyciel Internet Society Poland, pełnił funkcję Członka Zarządu ISOC Polska i Członka Rady Polskiej Izby Informatyki i Telekomunikacji. Był również członkiem Rady ds Cyfryzacji przy Ministrze Cyfryzacji i członkiem Rady Informatyzacji przy MSWiA, członkiem Zespołu ds. otwartych danych i zasobów przy Komitecie Rady Ministrów do spraw Cyfryzacji oraz Doradcą społecznym Prezesa Urzędu Komunikacji Elektronicznej ds. funkcjonowania rynku mediów w szczególności w zakresie neutralności sieci. W latach 2009-2014 Zastępca Przewodniczącego Rady Fundacji Nowoczesna Polska, w tym czasie był również Członkiem Rady Programowej Fundacji Panoptykon. Więcej >>






Tak tylko dla porządku przypomnę...
że w Netsprincie to funkcjonuje już od dawna i o protestach nie słyszałem. http://www.netsprint.pl/serwis/news
Jest różnica w proporcjach
Jeśli dobrze patrzę to jest jednak zrobione wyraźnie skromniej: Netsprint w większości daje tylko tytuł i link -- fotki czy nawet kilka słów leadu występują rzadko.
Natomiast w obu serwisach w ogóle nie widzę leadów w klasycznym sensie (kilka zdań, które jest wydzielone przez redakcję oryginalnego newsa), jest to raczej pierwsze ileś wyrazów, czyli automatyczny lead wycinany z oryginału przez Netsprinta i Google.
IWP - jak zwykle
Gazeta.pl: Google donosi po polsku.
Punkt widzenia zalezy od punktu siedzenia...
Ze dwie uwagi:
1. Google ochoczo przegląda za pomocą automatów zawartość innych stron i później udostępnia je publicznie. Natomiast nie udziela licencji na dalsze automatyczne przetwarzanie tej informacji i udostępnianie jej. Kanały RSS ze strony Google News nie mogą być syndykowane na stronach WWW, na przykład. Ale można ich używać ,,lokalnie'' w programie agregującym RSSy.
2. Zauważyłem już jakiś czas temu, że niusy agencyjne na stronach news.google.com (w wersji US) otwierają się w domenie google.com. Dotyczy to na przykład AP która ma specjalną domenę ap.google.com.
Natomiast kwestia reklam... Ja rozumiem, że jest to sprawa najważniejsza w przypadku dostawcy informacji. Może nawet ważniejsza od samych informacji. Jeżeli lead mnie zaciekawi -- wejdę i dalej. A reklam i tak nie będę oglądał (albo dzięki sprytnemu automatowi, albo odpowiednio skupiając swoją uwagę).
Jak google to może, to na podstawie czego?
Jak google to może, to na podstawie czego?
Nie zgodzę się z tezą, że na podstawie prawa cytatu "Google powołuje się na prawo cytatu", uważam że jest regulacja szczególna - prawo przedruku, i posłużenie się prawem cytatu byłby obejściem prawa przedruku. Jest jeszcze kwestia art. 4 pkt. 4 pr. autor.
300 to ściema
Zauważcie, że nie można dodać żadnego serwisu. Nigdzie nie jest publikowana lista tych 300 stron. Po prostu blaga
rss na stronie
przychodzę tu od niedawna i na wstępie chciałbym podziękować autorowi strony za tak wspaniałe źródło wiedzy na tematy prawne związane z internetem.
moja żona posiada kilka stron internetowych o charakterze informacyjnym (nie podaje adresów gdyż i tak są obecnie w przebudowie), chcąc uniknąć problemów natury prawnej zdecydowała się na niepublikowanie kanałów rss "wprost na stronie" tak aby były dostępne dla każdego. Strona diametralnie zmienia się jednak po zalogowaniu użytkownika. Oprócz nowości lokalnych (dotyczących regionu) publikowanych przez ją oraz jej znajomych, pojawia się masa informacji o tym co dzieje się na świecie i w kraju z takich serwisów jak onet.pl, wp.pl, gazeta.pl, a także z innych lokalnych stron internetowych. Są to absolutnie pełne treści umieszczone w rss-sie często wraz ze zdjęciem.
No i teraz sprawa następująca. Ze względu na optymalizację czasu wykonania się aplikacji generującej stronę, zdecydowała się na ściąganie tych informacji do siebie i przechwoywanie ich w bazie danych wraz ze zdjęciami. Oczywiście nie zmienia to w żaden sposób formy ich prezentacji. Prezentowane są w stanie "nienaruszonym" wraz z linkami do innych stron. Chciałbym więc zapytać czy Waszym zdaniem jest to naruszenie prawa?
Ani ja, ani żona prawnikami nie jesteśmy, stąd staraliśmy się wytłumaczyć sytuację na przysłowiowy chłopski rozum, czy aby faktycznie nie dochodzi do naruszenia prawa, w taki oto sposób.
Ponieważ część serwisu dostępna jest jedynie dla zalogowanych użytkowników, oznacza to niejako, że użytkownik wykorzystuje stronę jako aplikację do przeglądania kanałów. Normalnemu użytkownikowi nie wolno chyba zabronić aby przeglądał na swoim komputerze lokalnym takie informacje za pomocą czytnika rss bo przecież one właśnie tak działają (ściągają informacje na dysk). Pojawia się więc pytanie czy w razie ewentualnego sporu dla sądu może mieć to znaczenie że informacje te są na serwerze zdalnym a nie dysku użytkownika?
Dlaczego o tym piszę w ogóle? Otóż nie tak dawno właściciel konkurencyjnej strony zakazał nam wykorzystywania jego kanału. Dla mnie oznacza to mniej więcej tyle co sytuacja, w której pisze do mnie właściciel jakiegoś portalu z prośbą o usunięcie swojego adresu z czytnika rss, gdyż używam czytnika który serwuje nie jego reklamy obok treści z xml-owego feed-a, a autora oprogramowania, z którego korzystam!
W tej sytuacji (choć jak wspomniałem problem tymczasowo nie istnieje, ze względu na pracę nad serwisami) odpisaliśmy temu panu, że pod żadnym pozorem jego rss-ów nie usuniemy z serwisu bez prawomocnego wyroku sądu. Na razie nic się w tej sprawie nie dzieje, ale gdy strony znowu ruszą problem wróci...
Czy powinniśmy się ugiąć w takiej sytuacji?
Z góry dziękuję za odpowiedzi i pozdrawiam.