Mam się cieszyć, czy martwić?
 Netsprint uruchamia nowy serwis wzorowany na news.google.com. Prezentuje ostatnie wiadomości opublikowane w innych serwisach. Mój serwis został wyróżniony i od kilku dni jest zasysany przez skrypty Netsprinta. Zasysany z regularnością dość zastanawiającą... W mojej głowie pojawiają się pewne dylematy dotyczące przyszłości.
Netsprint uruchamia nowy serwis wzorowany na news.google.com. Prezentuje ostatnie wiadomości opublikowane w innych serwisach. Mój serwis został wyróżniony i od kilku dni jest zasysany przez skrypty Netsprinta. Zasysany z regularnością dość zastanawiającą... W mojej głowie pojawiają się pewne dylematy dotyczące przyszłości.
Agregatory i "nowi pośrednicy" (tacy jak wyszukiwarki) budzą wiele kontrowersji na świecie. Jak widać światowe problemy pojawiają się też na polskim podwórku. Nie tak dawno Gazeta.pl relacjonowała początek sporu między wydawcami prasy a agregatorami informacji: "Światowe Stowarzyszenie Wydawców Gazet rozpoczęło kampanię lobbingową wymierzoną przeciwko działaniu agregatorów informacji, takich jak Google News - poinformowała agencja Reutersa". I dalej: "Stowarzyszenie, do którego należą też polskie organizacje - Izba Wydawców Prasy i Stowarzyszenie Gazet Lokalnych - sprzeciwia się praktykom stosowanym przez Google News. Serwis automatycznie ściąga tytuły, zdjęcia i fragmenty artykułów i tworzy z nich portal informacyjny. Google linkuje do pełnej wersji tekstów, zamieszczonej na stronie wydawcy i nie wyświetla w obrębie serwisu reklam. Mimo to wydawcy uważają, że to naruszenie ich praw autorskich - To budowanie nowego medium żerującego na naszym przemyśle bez żadnej zapłaty za tworzoną przez nas zawartość - powiedział w wywiadzie dla Reutersa Ali Rahnema, dyrektor zarządzający stowarzyszenia"
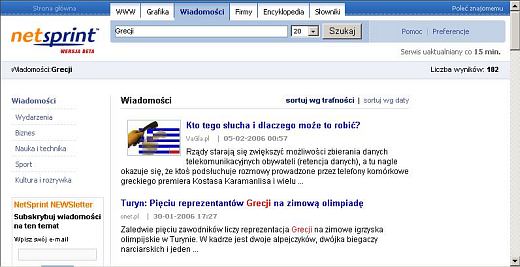
Serwis Wiadomości Netsprint.pl uaktualniany jest co 15 min., ale roboty skanują serwisy znacznie częściej. Powyżej nagłówek mojego newsa (wraz z grafiką, nad którą pracowałem przez dłuższą chwilę) opublikowany w serwisie Netsprint 10 minut po jego opublikowaniu u mnie. Być może zyskam przez to nowych czytelników. A może jedynie serwis będzie wolniej działał ze względu na aktywność robotów?
Pytanie tylko, czy faktycznie jest to coś czemu należy się przeciwstawiać? Istotnie - serwis wykorzystuje grafiki, i prezentuje je ze swojego serwera. Pytanie, czy robi to w ramach licencji ustawowej (a ta mówi o aktualnych zdjęciach reporterskich, nie zaś o infografikach, a i to można wyłączyć stosownym zastrzeżeniem)? Prezentuje też fragmenty tekstów, ale przecież mamy coś takiego jak prawo cytatu. Fragmenty nagłówków zresztą sam udostępniam w ramach serwisu RSS. Niejako one służą wręcz do tego, by z nich korzystać. Sam często korzystam z serwisu news.google.com w poszukiwaniu wątków informacyjnych dotyczących ostatnich zdarzeń. Ba! W ramch tego serwisu przecież udostępniam zalogowanym userom agregator RSS (chociaż nie "ciągnę" grafik, a jedynie udostępniane w tym celu nagłówki). Nieobecność zaś w takich serwisach oferowanych przez "nowych pośredników" może spowodować całkowite wyjęcie poza margines głównego nurtu debaty publicznej. Jak pisałem niedawno w sąsiednim newsie: "Rolę wydawnictw przejmują również systemy wyszukiwawcze. Okazuje się, że publiczność może nie mieć dostępu do informacji, jeśli przedsiębiorstwo oferujące wyszukiwarkę usunie ze swoich indeksów odesłania do określonych treści".
Drażni mnie crowler Netsprintu? Zawsze wszak mogę w pliku robots.txt ustawić stosowne prawa i problem znika (mam nadzieję). No ale też serwis nie pojawia się w mainstreemie informacyjnym, a więc staje się niewidoczny dla wielu, którzy w przeciwnym razie mogą do niego trafić przez agregatory. Zatem cóż. Cieszyć się popularnością? Popularność jednak kosztuje. Dziś wszak każdy pobrany bajt z serwisu jest wyceniany na żywą gotówkę. Wie to każdy, kto hostuje serwis w firmie, która w ramach umowy godzi się na określony, miesięczny transfer danych. Gdy serwis cieszy się zbyt dużą popularnością, to w połowie miesiąca można zobaczyć komunikat, że limit został wykorzystany i, by serwis był nadal widoczny dla odwiedzających, jego wydawca winien zapłacić kasę firmie udostępniającej łącze...
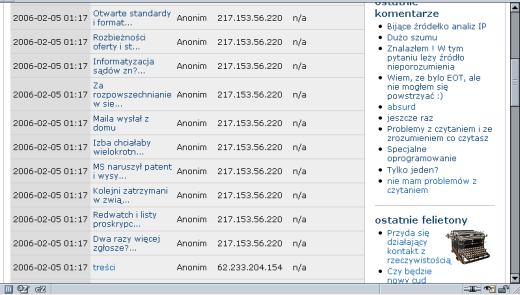
Roboty netsprint.pl (217.153.56.220) zostawiają ślady w logach. Regularnie skanują, pobierają, indeksują treści innych serwisów.
O jakim transferze można mówić? To policzyli panowie z serwisu strony.pl (sami uruchamiając wyszukiwarkę indeksującą inne strony): "Policzmy… Średni „pobór transferu” związany z indeksacją jednej strony serwisu to 25kB. Niech na serwis składa się 1000 podstron. Jednorazowa indeksacja całości wymaga zużycia 25 Mb z dostępnego limitu transferu. Przyjmijmy, że pełna reindeksacja ma miesce raz w miesiącu, a serwisem są zainteresowane jedynie roboty GYMON - sposród setek krążących w sieci. Jaki jest roczny koszt obecności serwisu w pięciu bazach? Po zaokrągleniu w górę - 100 zł.". Ja zaś mam prawie 6 tysięcy podstron, robot agregatora takiego jak Netsprint reindeksuje sajt co 15 minut (chociaż zdaje się, że dla potrzeb serwisu Wiadomości jedynie stronę główną serwisu)... Może jednak należy te roboty blokować przez robots.txt, gdyż nie jestem organizacją pożytku publicznego i nie mogę przyjmować od entuzjastycznie nastawionych użytkowników 1% ich podatku dochodowego, a jakoś tak dziwnie nie mam ochoty wpuszczać tu reklamy?
Zresztą plik robots.txt może mieć też wpływ na prezentowanie reklam w serwisie (w tym serwisie żadnych reklam nie prezentuję, ale jak zwiększy się jeszcze ruch na serwerze, to będę musiał się jakoś zatroszczyć o środki na jego utrzymanie, bo stanie się dość kosztownym hobby). W FAQ Google czytamy: Jeśli Twoja strona używa pliku robots.txt, robot AdSense może być przez ten plik zablokowany. Dlatego możemy nie być w stanie serwować odpowiednich reklam na Twojej stronie. Na stronach, których nie możemy zaindeksować lub zrozumieć ich treść, mogą być wyświetlane reklamy organizacji charytatywnych, za które nie otrzymasz pieniędzy".
No i proszę. Duży ruch może być kłopotem, gdyż generuje koszty, które z czegoś trzeba pokryć. Blokada zaś spowoduje, że potencjalni czytelnicy nie trafią do serwisu przez takich pośredników jak wyszukiwarki i agregatory, a ponadto może spowodować brak możliwości zdobywania ewentualnego finansowania. Tak, wiem, że da się założyć odpowiednie klauzule wpuszczające wybrane roboty - np. Google - ale one też generują ruch i niewiadomo nawet, czy taka zagrywka z wpuszczeniem reklamy Google czy nawet Netsprintu (który najwyraźniej stara się kopiować sukces Google na polskim podwórku) kompensuje koszt wpuszczenia do serwisu robotów tych firm. Niezły rebus do rozwiązania... A niektórzy przecież płacą ciężką kasę za np. pozycjonowanie serwisów, by maksymalnie "wyżyłować" możliwość przekierowania potencjalnych użytkowników z wyników wyszukiwania...
Spam można blokować na serwerach pocztowych, ruch na witrynie można blokować na serwerze www (na marginesie - takie crawlery i ich aktywność da się na pewnym poziomie abstrakcji porównać z przesyłaniem niezamówionej informacji drogą elektroniczną). Świat się powoli zamyka. Następuje stopniowe grodzenie, a możliwość realizacji prawa do wolności słowa niestety kosztuje. Warto o tym czasem pomyśleć... Z drugiej strony nie dziwi mnie, że starych pośredników zastępują nowi, a społeczeństwo informacyjne, którego piewcy zadrukowaują nadal opasłe tomy rozważaniami nad jego rozwoojem i przyszłością, wymaga bardziej swobodnego obiegu informacji. Grodzenie za pomocą "własności intelektualnej" to pewien sposób na zarabianie na tym obiegu informacji.
Rach ciach i nawet niniejszy skromny wpis w blogu już zassany, zindeksowany i zaprezentowany. Idzie nowe.
Ja jeszcze nie wiem co zrobię z robotami Netsprintu, chociaż łechce mnie trochę po próżności, że mnie dopisali do swoich Wiadomości (to nie było celowe rymowanie, ale niech tak zostanie). Aż boję się pomyśleć co się stanie, gdy do swoich robotów dopisze mnie polska wersja news.google.com, którą – być może – niebawem uruchomią.
- VaGla's blog
- Login to post comments
Piotr VaGla Waglowski

Piotr VaGla Waglowski - prawnik, publicysta i webmaster, autor serwisu VaGla.pl Prawo i Internet. Ukończył Aplikację Legislacyjną prowadzoną przez Rządowe Centrum Legislacji. Radca ministra w Departamencie Oceny Ryzyka Regulacyjnego a następnie w Departamencie Doskonalenia Regulacji Gospodarczych Ministerstwa Rozwoju. Felietonista miesięcznika "IT w Administracji" (wcześniej również felietonista miesięcznika "Gazeta Bankowa" i tygodnika "Wprost"). Uczestniczył w pracach Obywatelskiego Forum Legislacji, działającego przy Fundacji im. Stefana Batorego w ramach programu Odpowiedzialne Państwo. W 1995 założył pierwszą w internecie listę dyskusyjną na temat prawa w języku polskim, Członek Założyciel Internet Society Poland, pełnił funkcję Członka Zarządu ISOC Polska i Członka Rady Polskiej Izby Informatyki i Telekomunikacji. Był również członkiem Rady ds Cyfryzacji przy Ministrze Cyfryzacji i członkiem Rady Informatyzacji przy MSWiA, członkiem Zespołu ds. otwartych danych i zasobów przy Komitecie Rady Ministrów do spraw Cyfryzacji oraz Doradcą społecznym Prezesa Urzędu Komunikacji Elektronicznej ds. funkcjonowania rynku mediów w szczególności w zakresie neutralności sieci. W latach 2009-2014 Zastępca Przewodniczącego Rady Fundacji Nowoczesna Polska, w tym czasie był również Członkiem Rady Programowej Fundacji Panoptykon. Więcej >>






Teraz ruch Netsprinta :)
Drobny dodatek w serwisie i output Netsprinta też uległ zmianie... :) Przygotowaliście Panowie (i Panie, jeśli też w tym brały udział) nieelastyczne mechanizmy zasysania treści z wybranych serwisów. To świadczy o tym, że to takie zwykłe "ciągnięcie" treści "na siłę", nie zaś wykorzystywanie udostępnionych przez operatora strony mechanizmów (np. rss) ;>
Teraz każdy lead zastąpiony został przez komunikat: "Przekaż 1% swojego podatku dochodowego bezpośrednio » » wybranej organizacji pożytku publicznego"
Teraz pewnie zmodyfikują ssawki, by im nie psuły koncepcji :)
--
[VaGla] Vigilant Android Generated for Logical Assassination
Hehe. Już poprawili...
No prosze. Netsprint poprawił już mechanizm ssący :) Już się leady pokazują inne niż anons dotyczący 1% podatku i organizacji pożytku publicznego :) Tylko się trochę daty newsów przesunęły po reindeksacji poprzednich ;)
Muszę teraz wymyśleć coś nowego :)
--
[VaGla] Vigilant Android Generated for Logical Assassination
Rozwiązanie
Problem byłby do rozwiązanie tylko roboty i strony musiałaby zaimplementować to rozwiązanie. Programista umieszczałby na stronie pliczek UPDATED.php (rozszerzenie jest nieważne), który generowałby pliczek XML zawierający informację, kiedy jaka podstrona została zaktualizowana. I tak ten serwis netsprintu zamiast zasysać co jakieś kilka minut cały kanał RSS, zasysałby plik, który raczej nie przekroczyłby 1KB.
Wiele serwisów już
Wiele serwisów już generuje mapy stron XML zawierające m.in. informację o częstotliwości aktualizacji i dacie ostatniej modyfikacji. Obsługuje to Google, Bing, Yahoo, Ask.com, z polskich wyszukiwarek żadna.